Back Propagation(오차 역전파, BP)
BP의 목표 : 순방향(feed-forward) 네크워크에서 에러 함수 E(w) 의 그라디언트를 가장 효율적으로 구하는 식을 구하자. 입니다!
순방향 예측(Feed-forward Propagation Inference, FP)에서 나온 예측 값을 통해 네트워크의 Loss function L(w)의 Gradient를 효율적으로 구하는 algorithm입니다.
저는 BP를 학습 그 자체라고 이해하였습니다.
역전파는 경사하강법과 같은 Optimizer를 통해서 오차가 최소화되는 방향으로 가중치를 update한다. 라고 한 줄 요약할 수 있을 것 같습니다.
1) BP를 통해 기울기를 구한다.
2) Opimizer가 BP를 통해 구한 기울기를 사용하여 trainable parameter를 update한다.
어느 방향으로? loss function이 주는 방향으로
위 두개는 병렬적으로 작동합니다. 기울기를 구하고 Optimization을 하게 됩니다.
trainable parameter(weight, bias)를 loss function을 줄이는 방식으로 update 하는 것을 BP라고 생각하시면 편할 것 같습니다.
+ 순전파 시 활성화 함수의 값을 저장해두고, 역전파 시 출력층에서 입력층으로 계산하고 저장합니다.(Dynamic Programming)
Optimizer
손실함수를 줄여나가면서 학습하는 방법은 어떤 Optimizer를 사용하느냐에 따라 달라집니다. 경사하강법(Gradient Descent)은 가장 기본적이지만 가장 많이 사용되는 최적화 알고리즘입니다.

- Grarient Descent
- SGD
- momentum
- adagrad
- RMSProp
- adam
- 등등.. 많습니다. 추후 정리할게요 😄
BP의 수식적 표현

이번 포스트에선 w10과 w1의 기울기를 구해보도록 하겠습니다.
Loss function은 MSE를 가정하고 수식을 정리해보도록 하겠습니다.


Weight update

위와 같이 모델이 구성되어 있고 그림과 같이 순전파를 진행해 보도록 하겠습니다.
d는 각 입력 값과 가중치의 곱들의 합입니다. n은 활성화 함수입니다. 즉 비선형 변환을 의미하게 되는 것이지요.
순전파는 앞에서부터 진행되게 됩니다. 천천히 구해보도록 하겠습니다. 😄

먼저 인풋 데이터를 받게 됩니다. 현재 가정하고 있는 값은 x1 = 0.1, x2 = 0.2입니다. 받은 인풋 데이터는 Hidden layer 층에 들가기 전 weight들과 가중합을 하게 되면 위와 같은 수식과 값이 나오게 됩니다!
그러고 비선형 변환을 이루기 위해 저희는 Sigmoid라고 가정을 하고 진행을 해보도록 하겠습니다.
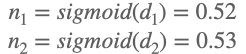
sigmoid function을 통해 비선형변환을 진행하게 되면 위와 같은 값이 나오게 됩니다.


순전파를 전체적으로 진행하게 되면 이러한 수식이 나오게 됩니다!
이제 예측 값까지 구했으니 이번엔 MSE loss function을 통해 실제 정답과 예측값의 차이를 구하겠습니다.

여태 저희는 순전파에서 구할 수 있는 계산들을 모두 해보았습니다!
이제부터 역전파를 통하여 weight를 Update를 해보도록 하겠습니다!
Layer의 층이 두 개
이기 때문에 두 번에 나누어서 Update하도록 하겠습니다.



수식에 대한 따로 설명을 하지는 않지만 전개하다보시면 이렇게 되는 구나 뒤에서 업데이트가 어떤식으로 되는 구나를 알 수 있으실 겁니다!
한 줄 요약 weight는 -lr * gradient만큼 변하게 됩니다.😄
혁펜하임님의 유튜브 강의 _https://www.youtube.com/playlist?list=PL_iJu012NOxdDZEygsVG4jS8srnSdIgdn
혁펜하임님 패스트캠퍼스 강의 _(https://fastcampus.co.kr/data_online_aideep)
Back Propagation _https://wikidocs.net/37406
Back Propagation _http://norman3.github.io/prml/docs/chapter05/3.html
Back Propagation _http://wiki.hash.kr/index.php/%EC%97%AD%EC%A0%84%ED%8C%8C
Optimizer _https://heeya-stupidbutstudying.tistory.com/entry/ML-%EC%8B%A0%EA%B2%BD%EB%A7%9D%EC%97%90%EC%84%9C%EC%9D%98-Optimizer-%EC%97%AD%ED%95%A0%EA%B3%BC-%EC%A2%85%EB%A5%98
Optimizer _https://heeya-stupidbutstudying.tistory.com/entry/ML-%EC%8B%A0%EA%B2%BD%EB%A7%9D%EC%97%90%EC%84%9C%EC%9D%98-Optimizer-%EC%97%AD%ED%95%A0%EA%B3%BC-%EC%A2%85%EB%A5%98
Calculator _https://www.desmos.com/scientific?lang=ko
'Machine Learning' 카테고리의 다른 글
| Adversarial learning의 갈래 (0) | 2023.07.20 |
|---|---|
| Deep Learning 분야 (0) | 2023.07.19 |
| 인공신경망이란 (0) | 2023.02.15 |
| 지도 학습 (0) | 2023.02.15 |
| AI란 (0) | 2022.12.20 |


댓글